During the election cycle, we assume that candidates have much control over the narrative of what they want to discuss, as it relates to their platform and their competitors. Yet, this is not the case. The media heavily influences the topics that are discussed during the election, whether the candidates brought it up or not. Furthermore, we as voters are bringing up topics that are relevant to us on places such as internet forums. What are these topics and how do they contribute to the Hype Machine? We’ve used natural language processing techniques to discover topics mentioned by the media and by voters on the Internet, and how they’ve influenced the primaries thus far.
What is Topic Modeling?
Topic modeling is a technique that clusters a collection of texts (such as sentences, paragraphs, and articles) into groups that are distinguished from one another by what these texts’ topics are. The model that we use for our analysis, Latent Dirichlet Allocation (LDA), will compute a probability of how each textual example is associated with each cluster. While LDA and topic modeling can’t tell us directly what the topic of each cluster is, we have the tools and background necessary to discern this for ourselves.
We used two main sets of textual data to discover topics brought up during the beginning of the Democratic party’s 2020 primary election cycle. The first set are internet news articles related to the 2020 primary, so that we can understand what topics the media is interested in. The second set are comments from political and candidate specific subsections of Reddit (i.e. /r/politics), in which users are discussing politically related news articles or other media. Comments help us understand what topics that internet-saavy voters may be discussing. More information about data munging and modeling can be found in the Methodology section.
News Articles
We created a LDA model trained to categorize 100 topics. We choose a high number of topics so that we can filter down topics that are of little interest (such as Stephanopoulus) while still capturing as many useful topics as possible. The final topic count is 53.
For instance, we can detect discussion of the first Democratic Primary debate as seen in the following chart:
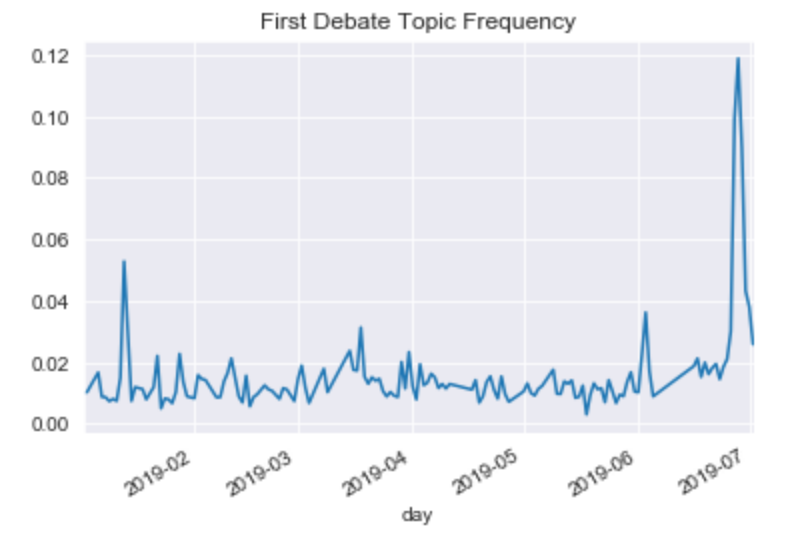
If you’d like to explore the model in detail, see the Methodology section below. What follows is the highlights of the model prediction and certain candidates including insights we can glean from how the media talks about candidates.
For instance, in the following chart we can see that the border as a % of topics has declined significantly. Part of the reason for this decline is the effects of new topics rising, such as many of the candidates announcing their runs for presidency.
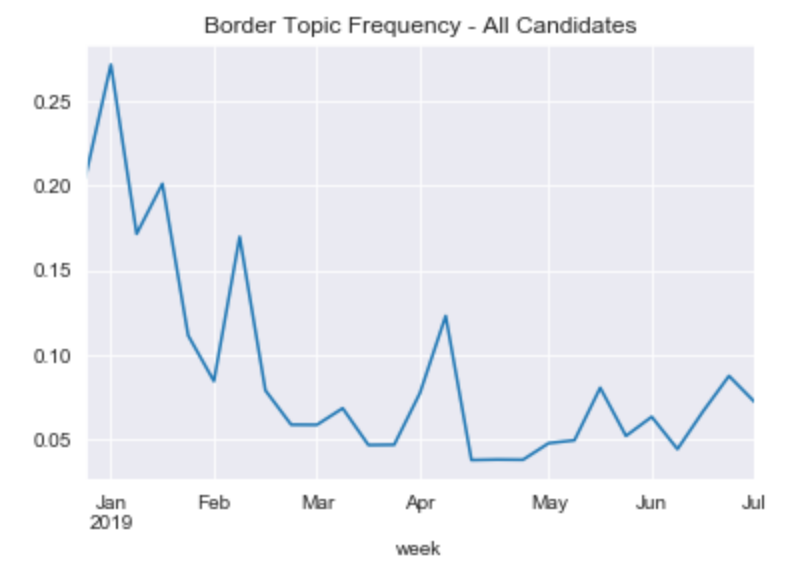
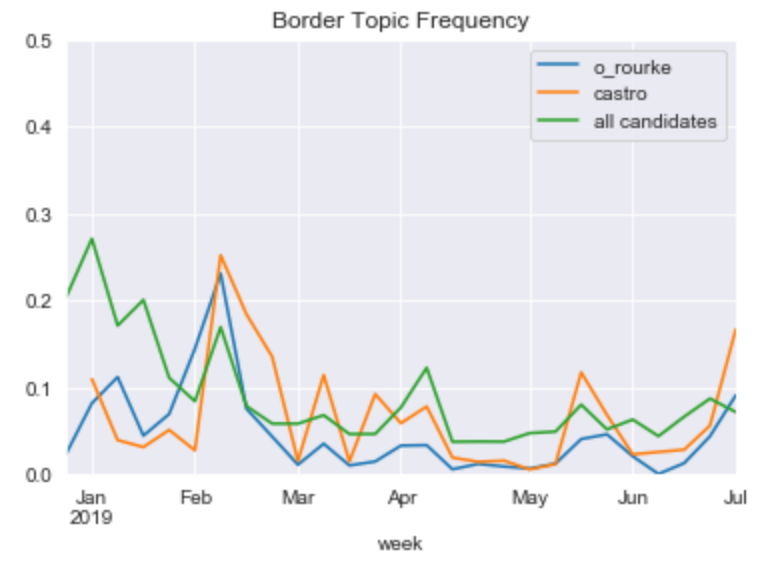
Also surprisingly, the Texan candidates who addressed border concerns in the debates do not get mentioned in the border topic any more frequently than the average candidate.
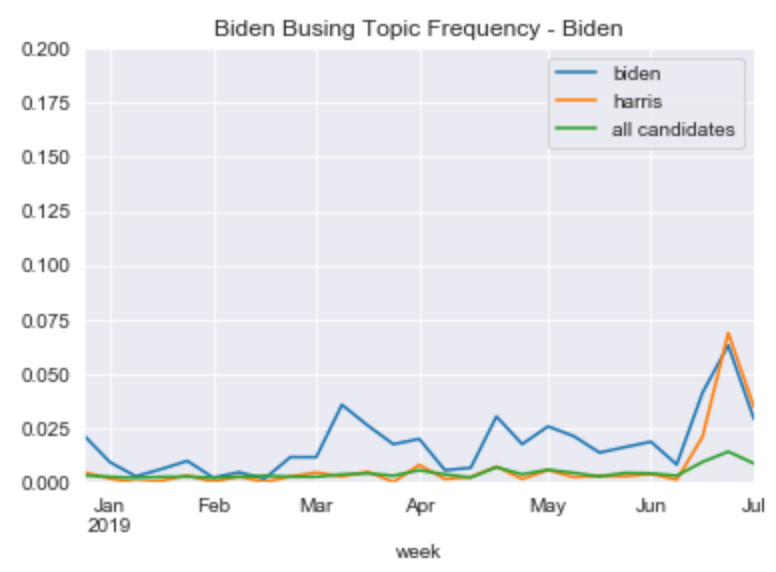
The model can be used to detect events. Many of the topics have spikes around the first Democratic Primary debate in late June 2019. For example, during the debate Kamala Harris had a viral moment when she attack Joe Biden on the topic of school busing in the late 20th century. We see for these two candidates a clear spike in the topic of “Biden Busing”, while for other candidates the spike is less remarkable (and also coincidental for these other candidates).
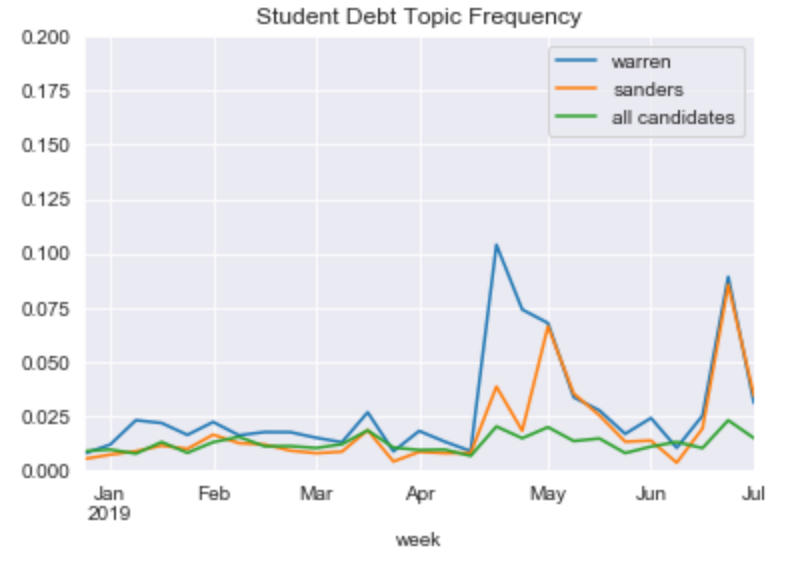
We can pick up on some of the candidates top topics. For instance, Sanders and Warren are outliers when it comes to the topic of student debt.
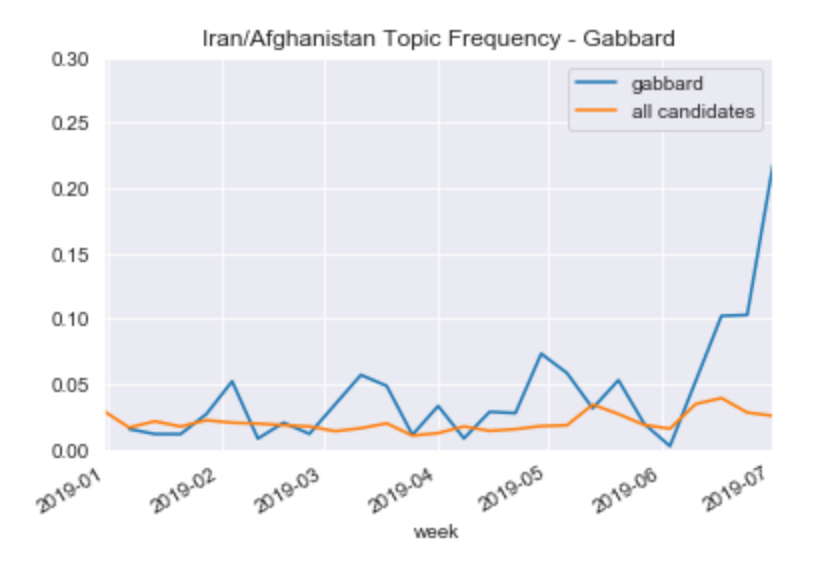
While Gabbard stands out on the topic of Iran:
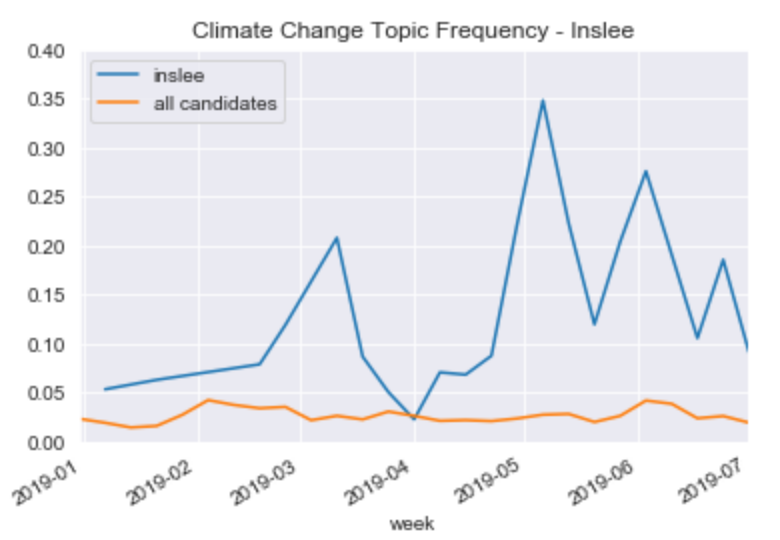
Jay Inslee is a climate change #1 campaigner. Here’s his relationship to that topic:
Generally, however we see that candidates in this latest leg of the 2020 primary are most often differentiated by identity and not policy. Here are the top words associated with each candidates topic:
Biden was spread amongst other topics, but he did have a busing topic:
biden, busing, would, school, oppose, senate, right, civil, support
Warren:
warren, elizabeth, massachusetts, senator, american, native, plan, policy, presidential
Harris:
attorney, prosecutor, officer, police, general, office, harris
harris, abortion, kamala, california, woman, right
Sanders:
sanders, democratic, party, bernie, candidate, campaign, progressive
sanders, campaign, iowa, event, bernie, crowd, hampshire
Buttigieg:
buttigieg, mayor, pete, south, bend
O’Rourke:
rourke, beto, orourke, texas, paso, city, cruz
Booker:
booker, cory, jersey, housing, home, senator, newark, mayor, latinx, city, community, black
Inslee:
inslee, climate, change, washington, governor, issue, state, seattle
Yang (mixed with Cuba):
yang, andrew, cuba, cuban, basic, drudge, income, automation, communist, entrepreneur, latin, universal, dividend
Williamson:
williamson, marianne, young, food, people, love, white, team, woman, spiritual, author
De Blasio:
york, city, blasio, cuomo, mayor
Hickenlooper (this got mixed with Pence and Billionaires due to topic size):
pence, hickenlooper, colorado, mike, hannity, gates, governor, bezos
Most of the candidate topics above are about the identity of the candidate, not their policy (with notable exceptions for Yang (UBI) and Inslee (Climate Change)). This tells us that the way the media talks about this wide Democractic field is through the candidates identity. It will be interesting to see as the field narrows if the tone shifts to more policy related ideas.
For more information, explore the model in the Methodology section below.
Reddit Comments
50 topics were chosen to train the LDA model on the Reddit comments. Overall, users on this internet forum are interested in discussing their thoughts and opinions, which tend to get clustered into their own topics:
Expressives
never, watch, enough, speak, stupid, throw, forget, truth
Perceptions
think, really, would, something, actually, thats, probably, understand
That being stated, there are still topics that discuss current events, the candidates, and some policy as well. Here are two topics surrounding current events:
The Russia Investigation
president, Mueller, report, evidence, Congress, investigation, justice, impeachment
Sexual Allegations
claim, completely, idiot, threaten, attempt, assault, sexual, behavior
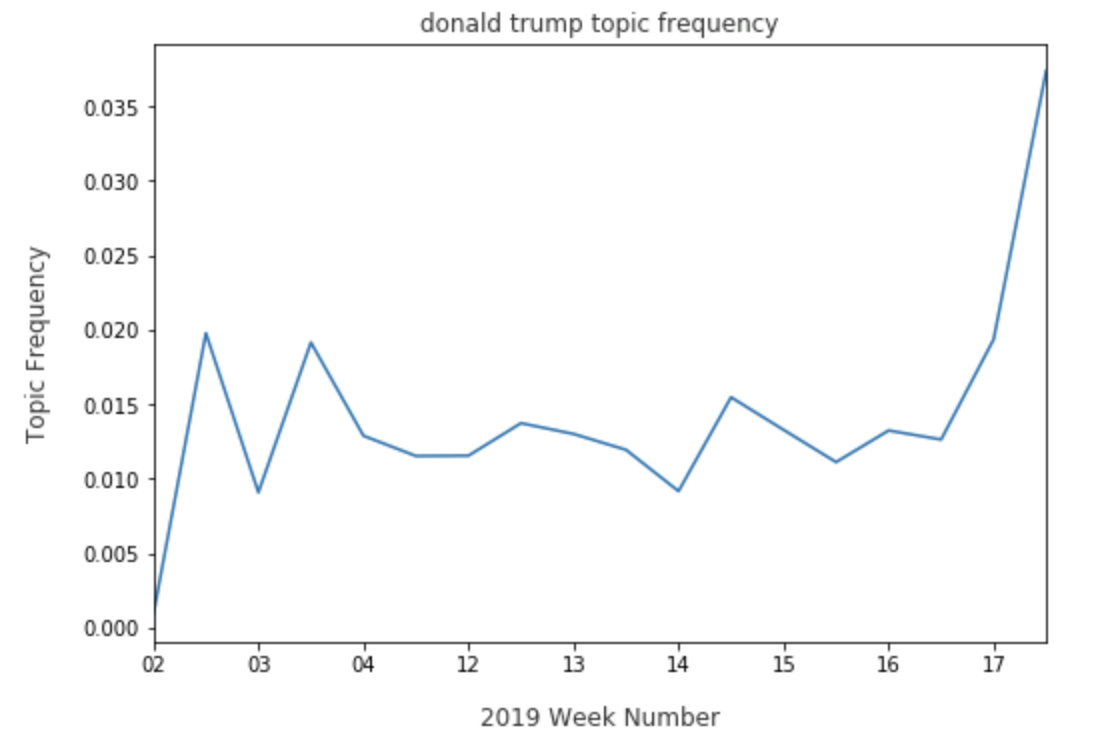
We’ll explore some of these topics as it pertains to one of the 2020 Democratic candidates, Elizabeth Warren. We can see what share she commands as it relates to topics around two competitors. With Donald Trump, Warren is consistently discussed with him and has seen a sharp increase in the beginning weeks of July:
With Bernie Sanders, Warren has a growing share, indicating that the two candidates are discussed in conjunction with one another.
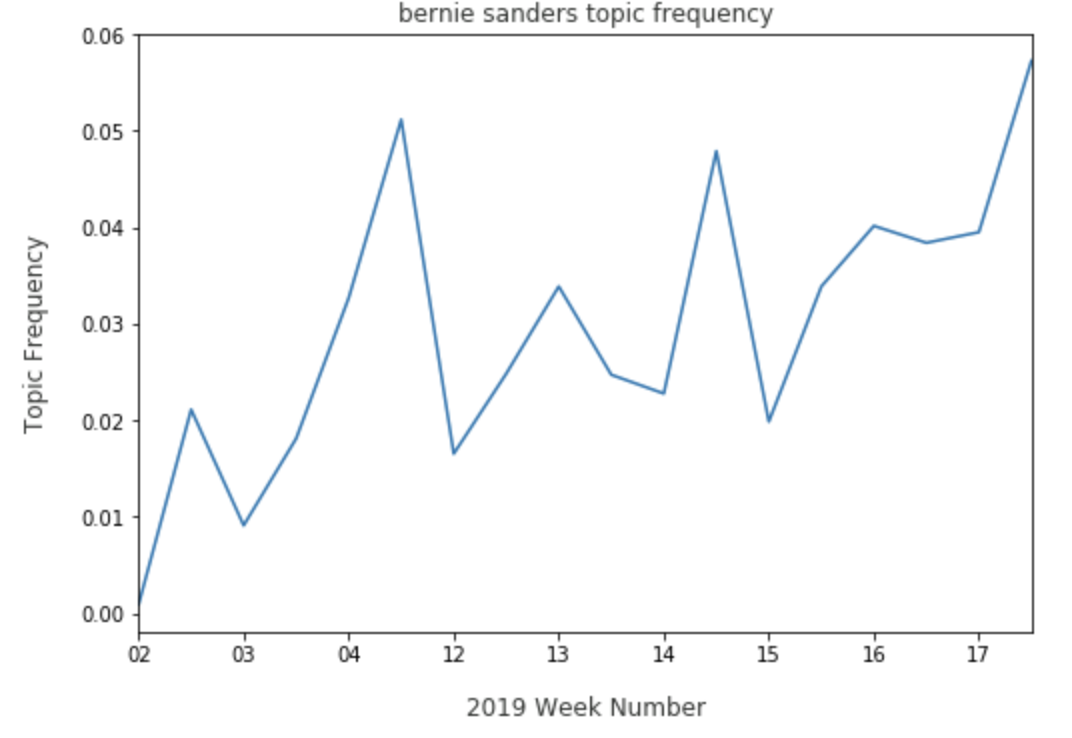
Tracking how Warren is discussed with other candidates gives a sense of how voters are comparing and contrasting her to the rest of the playing field. We can also view how Warren is discussed with higher level ideas, such as change:
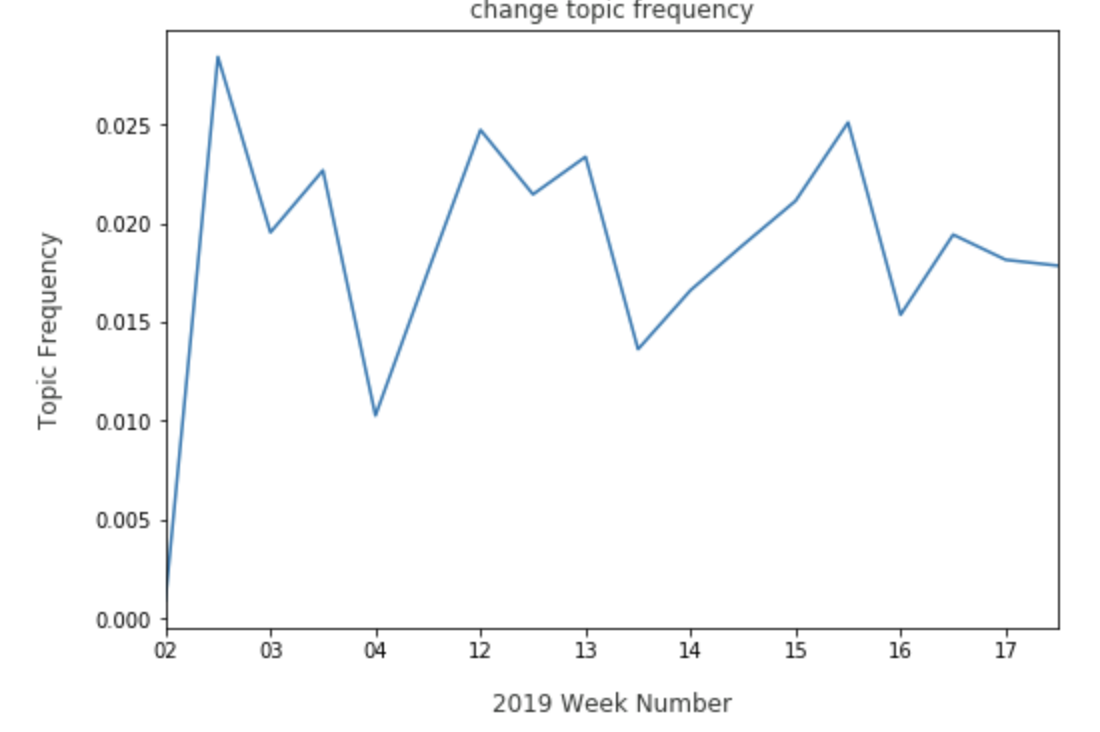
While Warren is frequently discussed with the concept of change, it may be useful to keep an eye on the trend, should she lose that share to a candidate who may be considered more exciting and promising. Warren can also come up in topics that are unexpected, but useful to review:
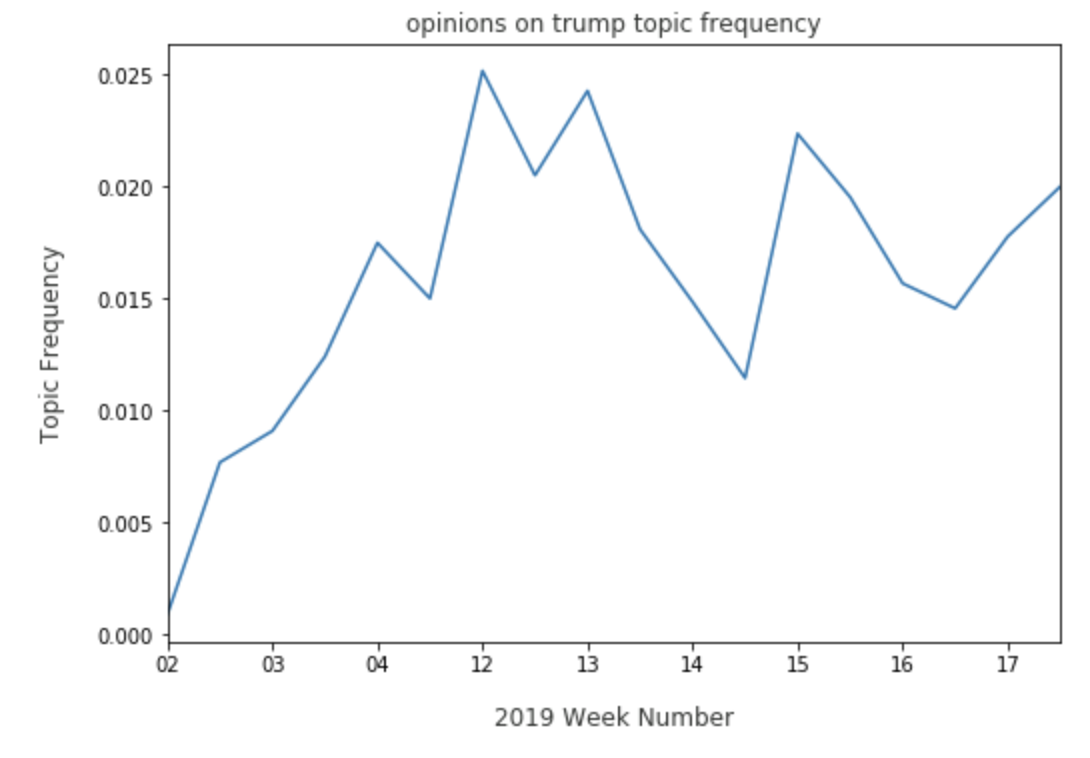
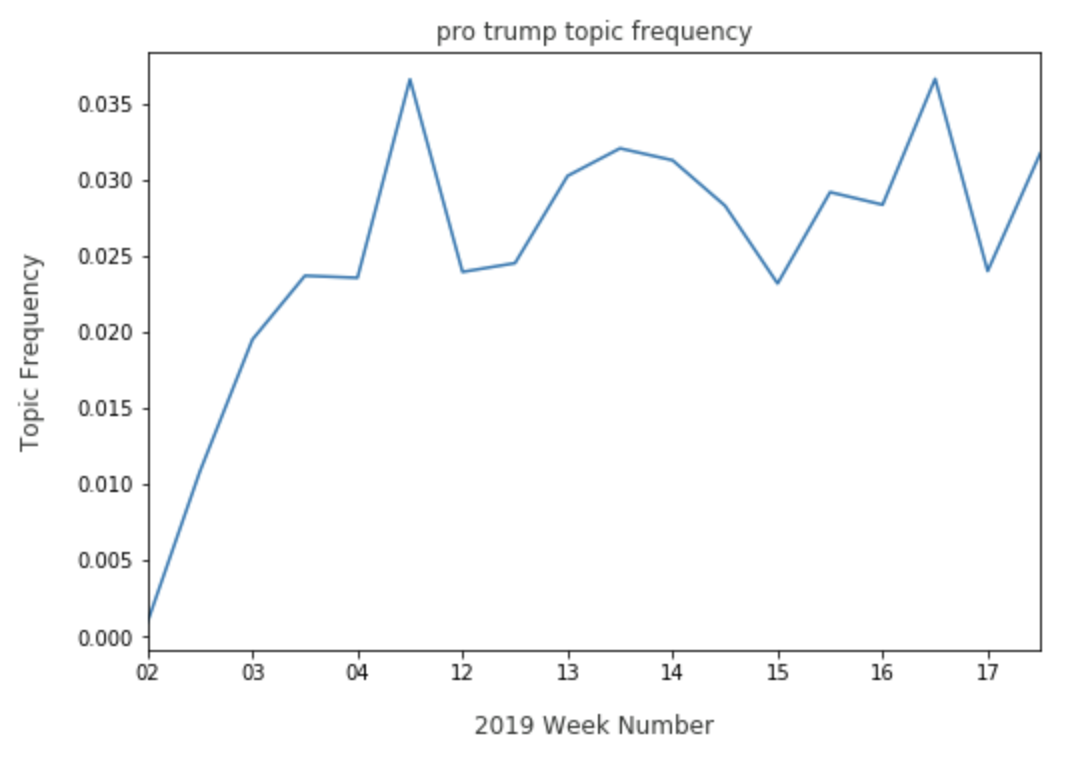
Elizabeth Warren trends well in both a topic expressing negative opinions on Trump, and on a topic that is specifically pro Trump. Finally, we can view where Warren may need improvement in comparison to other candidates. On the economy topic, Warren has a persistent presence:
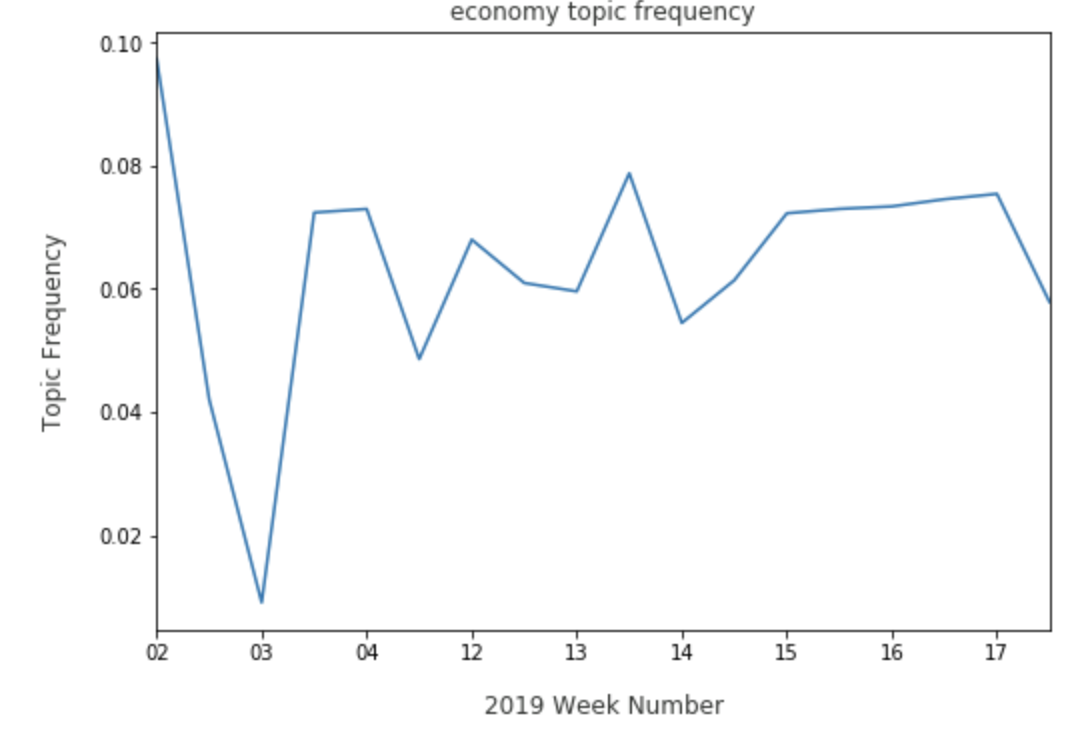
However, Warren may have to watch for Kamala Harris’ share in the economy topic, due to a recent spike:
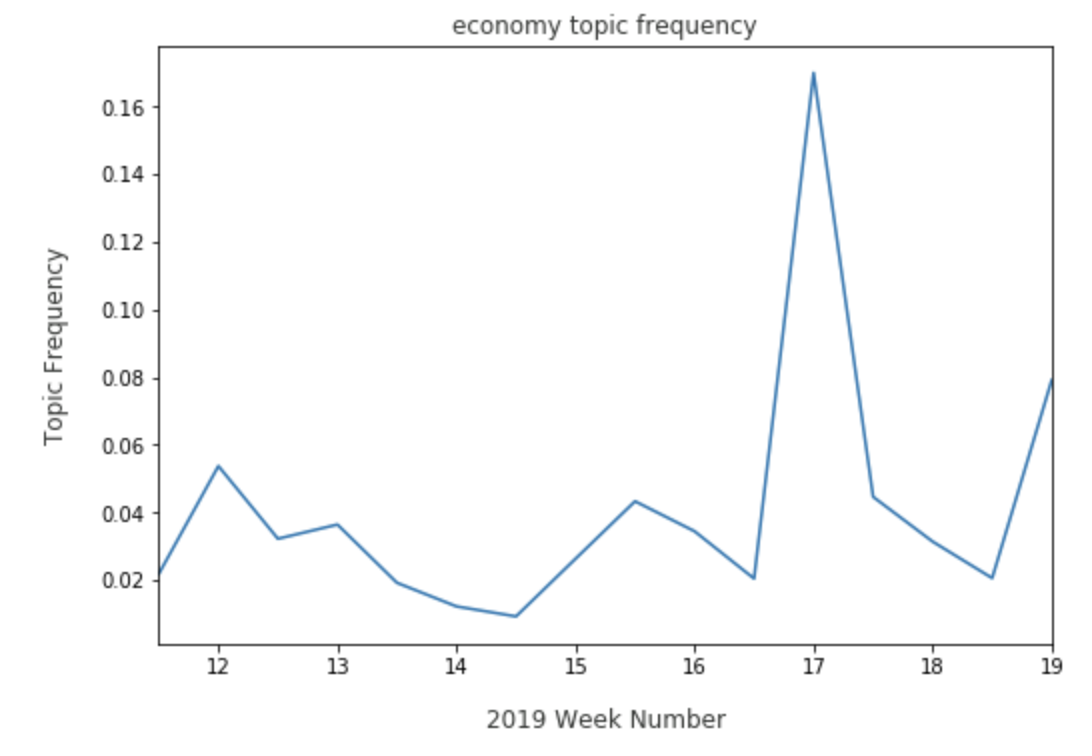
As for immigration, Warren has faltered just a bit:
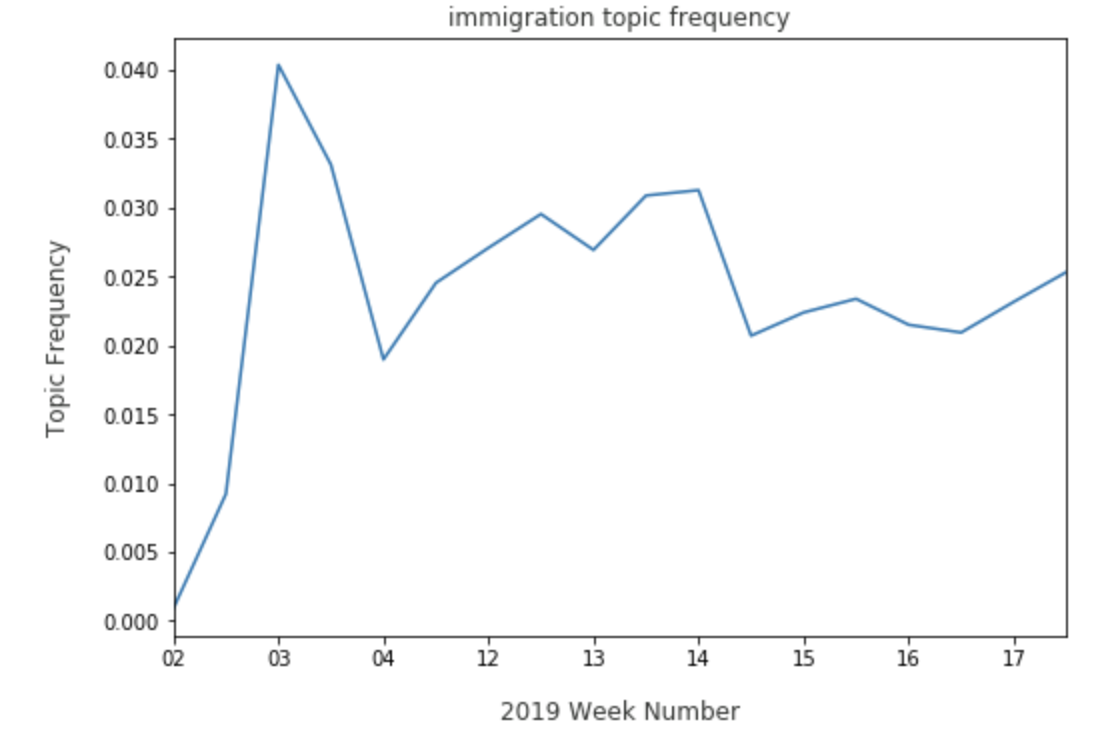
While Beto O’Rourke can be seen having better weeks:
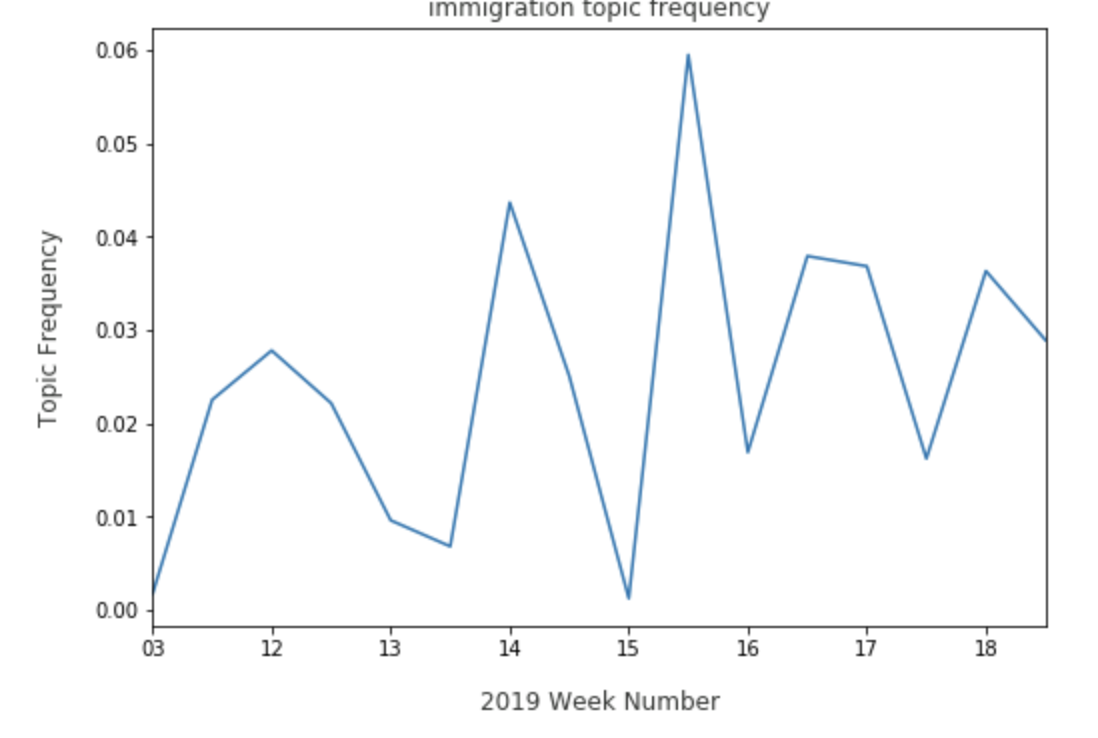
By viewing how a candidate like Elizabeth Warren is pervading the topics that come out of Reddit comments, we can see where she tends to come up in discussion and how discourse around her will change as the primaries continue on.
Unlike the topics that arose in News Articles, where identity politics dominates, Reddit’s comment section is more of a place to describe the voter’s feeling as it pertains to the candidates, their policy, or the current happenings around them. While there is potential for these topics to shift to identity or policy, the topics will most likely stay centered around feelings as voters discuss the 2020 Democratic Primary and its results leading up to the election against Trump.
Conclusion
Topic modeling allows us the ability to summarize discussions that are happening during the first couple months of the 2020 Democratic Primary. We’ve noted that the media is mainly focused on candidate identity, while voters on internet forums will continually discuss their feelings for the candidates, their policies, and the current political landscape leading up to the primaries. The Hype Machine will always be influenced by the voices that participate in it. Topic modeling definitely adds a way to get an idea of how the 2020 Democratic Primary will shape up.
Methodology
Datasets
We identified Reddit, and particularly politically related subreddits, as a rich source containing URLs to news articles that users will link to, as well as discussion about either those URLs, or other politically related topics that they would have in non-link posts called “self posts”. For two time frames, the 2016 Republican primary (January 1, 2015 to May 31, 2016, just before Donald Trump was announced as the Republican nominee) and the 2020 Democratic primary (January 1, 2019 to July 15, 2019), we look at content in /r/politics and the candidate of the specific party’s subreddits, if it existed. Examples include /r/KasichforPresident for the 2016 dataset, and /r/tulsi for the 2020 dataset. Because Donald Trump has been fundraising for re-election in 2020, we pulled content from r/The_Donald for both datasets.
We used Pushshift Reddit API to gather the data. For News Articles, we gathered link posts, the URL to the article, number of comments, and cumulative karma score. From there, we used news-please to scrape the article text from the URLs. For Reddit comments, we gathered all comments posted in the subreddits of interest for the dates specified, as well as cumulative karma score of each comment.
Cleaning and Pre-processing
We noticed that only 20% of the news articles failed to pull any data, but for those that did the data was complete. News articles were associated with candidates based on their commonly used name, which is usually their last name. Some notable exceptions are ‘Beto’ (O’Rourke), ‘Tulsi’ (Gabbard) and ‘Bernie’. Additionally, articles which mentioned both Castro and Cuba were removed due to Julián Castro sharing his name with Fidel and Raúl Castro. For the main LDA topic model we filtered out all news articles that did not mention at least one candidate (excluding Trump).
Raw reddit comments are left in there markdown forms, so the text had to be scraped of this formatting and converted to regular text. Comments may also be deleted or removed at a later time, which will be indicated by a [deleted] or [removed] in their comment body. These comments were removed from the dataset. Since karma score is a unique feature of Reddit, in which popular links and comments are “upvoted” and unpopular links and comments are “downvoted”, we wanted to provide this community feedback in our dataset. We did this by duplicating comments based on the log of their karma score. The most popular comments were duplicated up to ten times. Any comments less than 0 karma were removed. Finally, Reddit comments are featured in a tree structure, where the parent of the tree is in direct response to the link or main post, while children are typically in response to other comments. We chose to only keep the parent comments in order to reduce topic divergence.
For both articles and comments, text was stemmed, lemmatized, and converted to a corpus of Bag of Words for use in the model.
Modeling
After the Bag of Words has been created, we created several models:
News Models
In order to test proof of concept we created a 20 topic LDA model with all news articles (regardless of relevance to the 2020 primaries). This was largely successful as a proof of concept. We then truncated the news set down to articles containing 2020 Democratic Candidates and created 50-70-100 topic models with experimentation on other hyperparameters such as chunksize, passes and iterations. (See Gensim documentation for details). We found that 100 topics, 10 passes, 400 iterations and 2000 document chunksize created a model with enough features and apparent accuracy for finding interesting insights. The LDA model itself does not tag the topics so we tagged the topics ourselves. These tagged topics were then normalized (since 47 topics were removed) and aggregated into daily and weekly datasets. Here is a visualization of the model before we trimmed out 47 topics:
Comment Models
The comments model underwent similar experimentation in order to find the best combination of topics. Below is a visualization of the model done on Reddit comments: